Out of Character: Use of Punycode and Homoglyph Attacks to Obfuscate URLs
for Phishing
Out of Character: Use of Punycode and Homoglyph Attacks to
Obfuscate URLs for Phishing
Adrian Crenshaw
Introduction
One of the key components users leverage to tell if a URL is
part of a phishing attack is to compare the host and domain name to their
expectations for the legitimate site. For example, an email asking users to
summit bank information to a website with the domain name
AdriansHouseOfPwnage.com is not as likely to receive submissions as a website
that was hosted under a more reasonable sounding name. There are many common
techniques used currently and in the past to make links look more legitimate.
One would be to have the link text say one thing, but to have to anchor actually
point elsewhere, for example:
<a href=”http://irongeek.com”>http://www.microsoft.com</a>
The above is mitigated in many mail services by having the
actual link printed out next to the linking text if they differ. Another
technique is to confuse the users by modifying the URL to have a valid sounding
name in the credentials part of the URL, but the actual host name in the
trailing part:
http://www.microsoft.com@irongeek.com
Some modern browser mitigate this by either popping up a
warning (Firefox) or just refusing to see this format as a valid URL (Internet
Explorer). There are many more techniques that can be used to obfuscate a URL
however. The technique this paper will focus on is the use of Punycode and
homoglyphs.
Normally, DNS labels (the parts separated by dots) have to
be in the ASCII subset of just letters, digits and the hyphen (sometimes called
the LDH rule). Also, a label cannot start or end with a hyphen, and is case
insensitive. This limited set of characters causes a problem if someone wants to
use a character in a DNS label that is not part of the LDH character set.
Punycode, or more formally the Internationalized Domain
Names in Applications (IDNA) framework as it is used on the Internet, was
designed as a way to map characters that would normally be invalid in DNS host
names to valid characters. In this way, domain and host names can be created
using characters from a user’s native language, but still have them translated
into something the DNS system can use (assuming the application supports
decoding IDNA). Examples can be as simple as characters with accents such as
“café.com” (which browsers that support the IDNA specification will translate to
“xn--caf-dma.com”) to more complex ones where even the top level domain name is
not in ASCII, such as “http://北京大学.中國” (which converts to http://xn--1lq90ic7fzpc.xn--fiqz9s).
Explaining the IDNA algorithm and how it maps to Unicode symbols is beyond the
scope of this paper, and all an attacker need do is use one of the many online
generators to create a valid IDNA label. For more details on how the system
works, see RFC 3492. [1]
The second facet of this attack is homoglyphs. A homoglyphs is a symbol that
appears to be the same or very similar to another symbol. By extension, a
homograph is a word that looks the same as another word. Homoglyphs (look-alike
characters) can be used to make up homographs (look-alike words). If we were to
be pedantic this is not quite technically correct in a language sense, as the
different character makes the word not really be the same spelling. An example
of a homoglyph most would be familiar with is the letter O and the number 0.
Depending on the font used they may be hard to distinguish from each other. The
letters l (lower case L) and I (uppercase i) are another common example. Where
it becomes even more interesting are the places in Unicode where very similar
characters exist from different languages. Languages that use characters which
look similar to the normal Latin alphabet with diacritic accents, letter-like
symbols and other useable homoglyphs pop up with great regularity, some seeming
to be almost exact duplicates of the same symbol. Cyrillic script is a common
example, possessing very close homoglyphs for a, c, e, o, p, x and y. Even the
Latin alphabet appears twice in Unicode. The characters:
!"$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~
are represented in both the U+0021-007E (Basic Latin) and the U+FF01-FF5E
(Full width Latin) ranges of Unicode. This means changing from one encoding for
a given Latin character to the other is as easy as adding the decimal value
65248 to the lower range versions. Depending on the font used mixing character
families this way may cause a “Ransom Note” like visual effect because the exact
vertical and horizontal spacing of the characters may vary.
While the intended purpose of IDNA is to allow for internationalized DNS labels
it can also be used to make a URL or host name appear more legitimate than it
really is. Because the Unicode representation may cause visual confusion for a
user, it could cause trust where there should be none. For example:
http://www.microsoft.com⁄index.html.irongeek.com
may look like a legitimate Microsoft URL, but on closer inspection it
redirects to a site that the author controls. This is because the third slash
symbol is not really a slash symbol at all ( ⁄ U+2044). The real DNS entry is:
microsoft.xn--comindex-g03d.html.irongeek.com
More obfuscated DNS names could be created by choosing
something less obvious than Irongeek.com, or by having the Punycode be in the
domain name itself. How could an attacker leverage this?
It should be noted that two resources in the bibliography
helped greatly to inspire this project. [2] [3] After finding out about the
topic of homoglyph attacks from these first two sources, we discovered some of
the earliest work done on the subject by Evgeniy Gabrilovich and Alex Gontmakher
in their paper “The Homograph Attack”. [4] Viktor Krammer did further work on
the subject in “Phishing Defense against IDN Address Spoofing Attacks” [5] in
2006, but the subject seems to have been popularized in the pen-test/hacker
community by Eric Johanson in his Shmoocon 2005 talk using a spoofed version of
the paypal.com domain name. [6] Since 2005 precautions against homoglyph based
spoofing attack have come a long way.
Approach
The core question was how do modern browsers handle these IDN strings? The
approach we took was fairly simple. We generated many potential attack URLs and
then test the following:
1. How different browsers show the Punycode in the URL bar.
2. How different mail systems show the URL when email is displayed.
3. How social networks render the URL.
Some of these IDNA DNS names were tested using a domain we
control (irongeek.com), while others were tested using the local hosts file in
lieu of making real DNS entries. Buying many domain names could become
expensive, and the local hosts file services most of the proposed tests
adequately (other than testing the policies of registrars in allowing certain
characters). We did some research into mitigations that are already in use to
quell these sorts of attacks as well as what mitigations might be possible, and
then tested them for effectiveness. Tools were developed to help generate the
attack URLs and released to the pen-test community to make research easier. This
is probably the main contribution of our project, and hopefully other
researchers will find it useful. These features could be a usefully addition to
the Social-Engineering Toolkit (SET) and other projects. [4] Kevin Johnson of
the SANS Institute already plans to use it in the Sec 642 class they offer.
Tools
Previously researchers who studied homoglyph based attacks
might use a tool like Windows Character Map tool (charmap.exe) or use one of
many websites online that allow the user to copy and paste the characters as
needed. Common character sets that are useful for homoglyph attacks (like
Cyrillic) might be saved into a text file and used to copy and paste from. To
make experimenting with Unicode homoglyph based homograph attacks easier for
researchers and pen-testers one of the goals for this class project was to make
a Homoglyph Attack Generator [5]. The Homoglyph Attack Generator is a JavaScript
and PHP based web applications that allows the user to type in a string and then
suggests homoglyphs for the user to choose to make a homograph. Most of the work
is done in JavaScript, with some backend PHP libraries to generate the IDNA
Punycode from the supplied Unicode strings. These PHP libraries were created by
phlyLabs as part of phlyMail [6]. Homoglyphs were chosen for the app based on
the authors own experience, the list at homoglyphs.net and user submissions.
Programming this tool greatly helped the efficiency of this research as it
allowed homographs to be quickly generated.
Work
When this project was first proposed by the author, we
expected there to be more clear flaws. Unfortunately for tricksters, attackers,
pen-testers and those with legitimate uses for IDNA it seems that the current
setting in most web browsers is to fail to display the Unicode version of a
domain name if there is any doubt, instead showing the Punycode.
Using the tools mentioned above, various homoglyph based
host names were created to test for how web browsers and web applications
displayed IDN values. Much work has been done to protect against IDN spoofing
attacks since 2005. Let us use Firefox as the first example.
For a host name to be displayed as its IDN and not
Punycode its Top Level Domain Name must be in the white list. These TLD values
can be seen by entering about:config into Firefox’s URL bar, hitting enter, and
filtering for “network.IDN.whitelist”. New whitelist values can be added to make
them display in their Unicode form, or “network.IDN_show_punycode” could be set
to true (the default is false). As of Firefox 11 the quite long default
whitelist includes:
.ac
.ar
.asia
.at
.biz
.br
.cat
.ch
.cl
.cn
.de
.dk
.ee
.es
.fi
.gr
.hu
..il
.info
.io
.ir
.is
.jp
.kr
.li
.lt |
.lu
.lv
.museum
.no
.nu
.nz
.org
.pl
.pr
.se
.sh
.si
.tel
.th
.tm
.tw
.ua
.vn
.xn--0zwm56d
.xn--11b5bs3a9aj6g
.xn--80akhbyknj4f
xn--90a3ac
.xn--9t4b11yi5a
.xn--deba0ad
.xn--fiqs8s |
.xn--fiqz9s
.xn--fzc2c9e2c
.xn--g6w251d
.xn--hgbk6aj7f53bba
.xn--hlcj6aya9esc7a
.xn--j6w193g
.xn--jxalpdlp
.xn--kgbechtv
.xn--kprw13d
.xn--kpry57d
.xn--mgba3a4f16a
.xn--mgba3a4fra
.xn--mgbaam7a8h
.xn--mgbayh7gpa
.xn--mgberp4a5d4a87g
.xn--mgberp4a5d4ar
.xn--mgbqly7c0a67fbc
.xn--mgbqly7cvafr
.xn--o3cw4h
.xn--ogbpf8fl
.xn--p1ai
.xn--wgbh1c
.xn--wgbl6a
.xn--xkc2al3hye2a
.xn--zckzah |
If a host name’s TLD is not in this list, it will not be
displayed in its Unicode form, but as Punycode instead (assuming
“network.IDN_show_punycode” is set to the default value of false).
An attempt was made by the author to see if perhaps the homoglyph attack could
be used against pseudo-TLD such as .onion and .i2p, but this seems impractical.
In the case of both Tor’s and I2P’s base32 address representation, there are
only certain characters that can be validly used. In the case or I2P’s Susi DNS
based addresses, since the I2P TLD is not in the white list any attempt to use
an IDNA shows up as Punycode. Even if a host name has a TLD name that is
acceptable for IDN display, Firefox 11 might still reject showing the Unicode
version and instead show the Punycode if any of these characters on in the
string:
¼½¾ǃː̷̸։׃״؉؊٪۔܁܂܃܄ᅟᅠ᜵
․‧
‹›⁁⁄⁒ ⅓⅔⅕⅖⅗⅘⅙⅚⅛⅜⅝⅞⅟∕∶⎮╱⧶⧸⫻⫽⿰⿱⿲⿳⿴⿵⿶⿷⿸⿹⿺⿻ 。〔〕〳ㅤ㈝㈞㎮㎯㏆㏟꞉︔︕︿﹝﹞./。ᅠ�
This inability to use ╱⧶⧸⫻⫽/〳limits some attacks where the attacker might try
to register an inconspicuous domain name, but use their control of host names in
that domain to trick the users. For example, the following URL:
http://www.microsoft.com⁄index.html.irongeek.org
Would be displayed as follows in Firefox 11:
http://www.microsoft.xn--comindex-g03d.html.irongeek.org/
Even though it is using a .org which is whitelisted, the use of ⁄ (U+2044)
instead of / (U+002F) causes Firefox to render it as Punycode.
To test out the functionality of browser in regards to how they showed
Unicode vs. Punycode we constructed many homographs and tested with IE 9.0,
Firefox 11.0 and Chrome 18.0.1025.142. The results are listed below, with the
top three lines showing:
1. The Unicode character(s) used.
2. The Unicode/IDN representation.
3. The ASCII/Punycode.
Ω U+03A9
Ω.com
xn--bya.com/
Firefox: Shows Punycode
IE: Shows Punycode
Chrome: Shows PunycodeΩ U+03A9
Ω.org
xn--exa.org
Firefox: Shows Unicode
IE: Shows Punycode
Chrome: Shows Punycode
北京大学.中國
xn--1lq90ic7fzpc.xn--fiqz9s
Firefox: Shows Unicode
IE: Shows Punycode
Chrome: Shows Punycode
ɡ U+0261
ɡoogle.com
xn--oogle-qmc.com
Firefox: Shows Punycode
IE: Shows Punycode
Chrome: Shows Punycode
ο U+03BF
gοogle.com
xn--gogle-rce.com
Firefox: Shows Punycode
IE: Shows Punycode
Chrome: Shows Punycode
о U+043E
gоogle.com
xn--gogle-jye.com
Firefox: Shows Punycode
IE: Shows Punycode
Chrome: Shows Punycode
е U+0435
googlе.com
xn--googl-3we.com
Firefox: Shows Punycode
IE: Shows Punycode
Chrome: Shows Punycode
G U+FF27
Google.com
http://xn--oogle-vk33a.com
Firefox: Normalized to standard Latin g
IE: Normalized to standard Latin g
Chrome: Normalized to standard Latin g
|
gU+FF47
google.com
xn--oogle-dq33a.com
Firefox: Normalized to standard Latin g
IE: Normalized to standard Latin g
Chrome: Normalized to standard Latin g
gU+FF47 oU+FF4F oU+FF4F gU+FF47 lU+FF4C eU+FF45
google.com
xn--qi7cdauna.com
Firefox: Normalized to standard Latin
IE: Normalized to standard Latin
Chrome: Normalized to standard Latin
ⅼ U+217C
googⅼe.com
xn--googe-xm5b.com
Firefox: Normalized to standard Latin g
IE: Normalized to standard Latin g
Chrome: Normalized to standard Latin g
lU+FF4C
google.com
xn--googe-cr33a.com
Firefox: Normalized to standard Latin g
IE: Normalized to standard Latin g
Chrome: Normalized to standard Latin g
eU+FF45
google.com
xn--googl-5p33a.com
Firefox: Normalized to standard Latin g
IE: Normalized to standard Latin g
Chrome: Normalized to standard Latin g
і U+0456
іucu.org
xn--ucU+ihd.org
Firefox: Shows Unicode
IE: Shows Punycode
Chrome: Shows Punycodeі U+0456
іsdpodcast.org
xn--sdpodcast-u9h.org
Firefox: Shows Unicode
IE: Shows Punycode
Chrome: Shows Punycode
|
As can be observed from the results above IE and Chrome
handle IDN a little differently than Firefox.
IE bases some of its decisions on whether to show the Unicode
or Punycode version of the URL on the preferred languages set in the browser’s
options. If there is a mismatch between the characters used in the URL and the
language expectation IE will give the user a warning “This Web address contains
letters or symbols that cannot be displayed with the current language settings”
as well as visual clues. Also figured into IE’s display decisions are whether
the character is used in any language (we will see more on this shortly), or a
mixed set of scripts that do not belong together (mixing Cyrillic and Latin for
example). Further details on IE’s support of IDN can be found on their support
page. [7]
Chrome’s details also differ. Chrome uses the configured
language of the browser (configured in the “Fonts and Languages” options) as one
component. Like Firefox, Chrome checks against a black list of characters, and
similar to IE, if two incompatible scripts are used then Punycode will be shown
in the address bar. There is also a whitelisting of some characters if the two
scripts are not likely to be confused (Latin with Chinese for example). Further
details on Chromes support of IDN can be found on the Chromium project’s support
page. [8]
Even if a browser decides to show a given URL as Unicode,
that does not mean that the registrar will let it be registered. For example,
one registrar gave the following error when an attempt was made to register
іucu.org (Cyrillic small letter Byelorussian-Ukrainian i U+0456):
“Error: You used an invalid international character! Please note that for some
reason .org and .info only support Danish, German, Hungarian, Icelandic, Korean,
Latvian, Lithuanian, Polish, Spanish, and Swedish international characters.”
While not all registrars may be as observant, this does not bode well for
finding a workable homograph to register. Based on the languages that .org is
said to support we did find a few close homographs based on homoglyphs from
those languages. With those we could build the following homographs that seemed
to be register-able and appeared in their Unicode form in Firefox :
Íucu.org [xn--ucU+2ia.org](Latin capital letter i with acute Í U+0456)
íucu.org [xn--ucU+qma.org](Latin small letter i with acute í U+00ED)
įucu.org [xn--ucU+9ta.org](Latin small letter i with ogonek į U+00ED)
Unfortunately (depending on your prospective) all three of
these appear in their Punycode form in IE and Chrome. From this we would
conclude that IE and Chrome are a little more resilient to Unicode based
homoglyph attacks, but even on Firefox there are some practical limitations.
Display of IDNA in Web Apps
While modern browsers seemed fairly robust to homoglyph
attacks if the user pays attention to the URL bars and mouse over indicators,
what is the state of web apps, email and social media sites? If an IDNA address
is used in a web app, email or social media context how will it be represented
in the body of the content? Doing an exhaustive test of all applications is of
course out of the scope of this paper, however there were some key ones we
decided to focus on because the author uses them on a daily basis: Outlook 2010,
Gmail, Twitter and Facebook. To test these out, we used the following strings:
Ω U+03A9
http://Ω.com
ɡ U+0261
http://ɡoogle.com
http://ɡoogle.org
і U+0456
іucu.org
http://іucu.org
⁄ U+2044
http://www.microsoft.com⁄index.html.irongeek.com
http://www.microsoft.com⁄index.html.irongeek.org
This set of strings was selected to test different character ranges (the
exact Unicode code point specified by the character used in the string and the
U+XXXX notation) and the effects of the TLD (Top Level Domain Name). The
following are screen shots of the results, along with a discussion of the
findings.
Outlook 2010
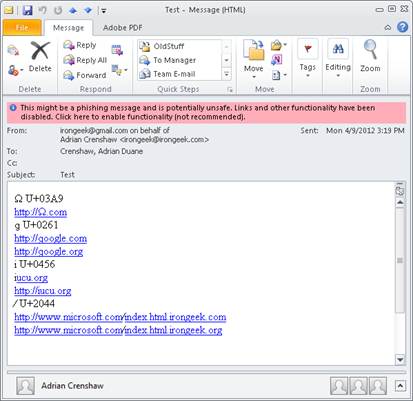
For testing Outlook we sent an email from a Gmail account to
a university email address and viewed it with Outlook 2010. The first thing the
reader might notice is the pink highlighted warning that reads “This might be a
phishing message and is potentially unsafe. Links and other functionality have
been disabled. Click here to enable functionality.” This helps mitigate some
risks, even if the user becomes “click happy”. For the first three links and the
fifth (http://Ω.com, http://ɡoogle.com, http://ɡoogle.org and http://іucu.org)
the auto link functionality does work, but the mouse over shows the Punycode
version of the URL in Firefox. For the fourth, seventh and eighth links (іucu.org,
http://www.microsoft.com⁄index.html.irongeek.com and http://www.microsoft.com⁄index.html.irongeek.org)
something a little stranger happens. The code that automatically parses the text
to create hyperlinks recognizes the ucu.org part of the URL, and links to
ucu.org, but the і (soft-dotted Cyrillic i U+0456) is not seen as part of the
URL unless it is preceded with http:// (as is the case with the fifth link). The
⁄ (fraction slash U+2044) also causes oddities in parsing for the sixth and
seventh URLs, causing them each to be linked to as two separate resources
(http://www.microsoft.com and http://index.html.irongeek.org for example). How
much of the parsing of the URLs was done on Gmail’s end and how much on Outlook
2010’s end is not certain.
Gmail
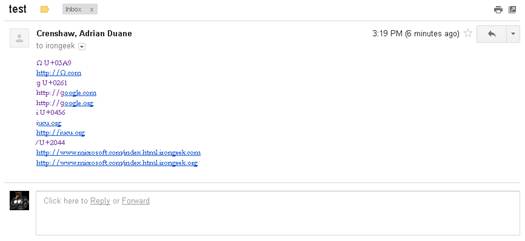
For testing Gmail we sent an email from a university email
address with Outlook 2010 and then read it in Gmail. The first and fifth URL
(http://Ω.com and http://іucu.org) come through as expected, but shows Punycode
on mouse over in Firefox. The ɡ (Latin small letter script G U+0261) causes a
parse oddity for the second and third URLs, causing them to be linked to as
http://oogle.com and http://oogle.org respectively. For the fourth, seventh and
eighth links (іucu.org, http://www.microsoft.com⁄index.html.irongeek.com and
http://www.microsoft.com⁄index.html.irongeek.org) we see the same auto linking
results as previously observed in Outlook 2010. How much of the parsing of the
URLs was done on Gmail’s end and how much on Outlook 2010’s end is not certain.
Twitter
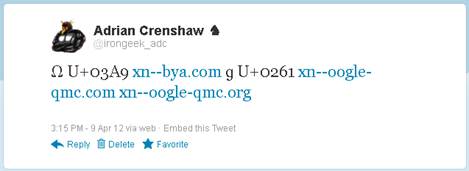
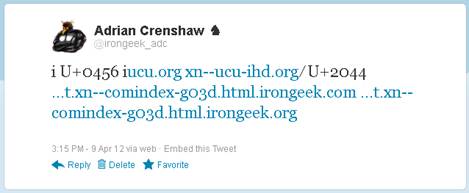
Twitter had the effect of rendering all of the URLs as a
truncated, URL shortened (using t.co), Punycode version, except the іucu.org
without the preceding http://. Again, the soft-dotted Cyrillic і (U+0456) seemed
to confuse the parser. Twitter makes it pretty obvious even from the body of the
message that there is something funny about the URLs.
Facebook
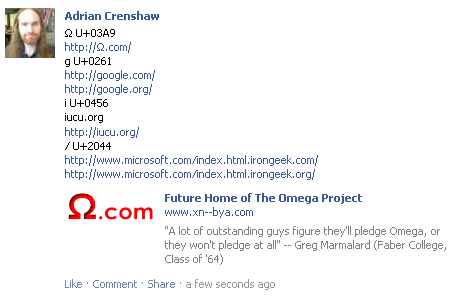
Facebook seemed to render all but the fourth link as it was
inputted, of course showing the Punycode on mouse over on all but the fifth link
(http://іucu.org with the preceding http://). The ⁄ (fraction slash U+2044) in
the last two links seem also cause no oddities, and face book linked to each as
the full string instead of separating them as Gmail and Outlook 2010 did. Again,
the soft-dotted Cyrillic і (U+0456) seemed to confuse the parser when it hit
іucu.org without the preceding http://, but instead of linking to http://ucu.org
it made no link at all.
General observations on application rendering of Punycode
While it is not immediately apparent how this may be used,
the differences in how various web and traditional applications render IDNA
addresses is worth looking into. This leads into the canonicalization issues
touched upon in the next section.
Suggestions for further study
Unicode homoglyph attack vectors for spoofing host/domain
names seem to have been fairly well studied, but are there other vectors of
attack where homoglyphs could be leveraged? Chris Weber gave a presentation
titled “Unraveling Unicode: A Bag of Tricks for Bug Hunting [9]” and a draft
paper named “Unicode Security Software Vulnerability Testing Guide [10]” at
Blackhat USA 2009. Unfortunately, when Mr. Weber was contacted to see if the
full paper was available it seems the Unicode paper had not progressed pass the
preview point. Still, Mr. Weber’s paper serves as a good starting point for
looking at other possible attack vectors using Unicode and puts forth the
following categories of potential vulnerabilities:
Visual Spoofing
Best-fit mappings
Charset transcodings and character mappings
Normalization
Canonicalization of overlong UTF-8
Over-consumption
Character substitution
Character deletion
Casing
Buffer overflows
Controlling Syntax
Charset mismatches
Unfortunately, not all of these are clarified in the draft
paper. One vector that definitely bares looking into is the
normalization/character mappings of user input into a Charset and application
uses. We saw this somewhat already in the section on web browsers where a URL
using full width Latin characters was automatically canonicalized into normal
Latin ASCII equivalent characters. How could an attacker use something similar
to this? For a hypothetical example, let’s say an application does filtering
first, looking for certain character like < or >, but it also tries to
canonicalize similar characters like < (U+003c), >(U+003e), ‹ (U+2039), ›
(U+203a), <(U+ff1c), >(U+ff1e) afterwards. Since the filter took place first
(when there was not a true character match because of having different Unicode
code points), but the conversion happen afterwards, this could possibly be used
for filter evasion. Keep in mind, this is just a hypothetical, we personally do
not know of a system that handles things quite this way.
Research we would personally like to continue to work on is
in the areas of steganography and username spoofing. A previous project of the
author’s used Unicode homoglyphs to make a steganographic command and control
channel [11] for a proof of concept botnet. Also, some work has been done on
testing web apps for username spoofing. For example, IP.Board, a popular web
forum software package, will not allow two different users to have the same
handle. Using Unicode homoglyphs however allows someone to make a visually
identical username. Similar attempts were made against Gmail and Twitter, but
the homograph names were rejected because of the non-ASCII characters. Twitter
returned the error “Invalid username! Alphanumerics only.” and Gmail/Google the
error “Please use only letters (a-z), numbers, and periods.” when non-ASCII
characters were attempted. More research needs to be done in these areas.
Conclusions
On the main subject of using Unicode homoglyphs and IDNA for
phishing attacks, it seems pretty hard in modern browsers to pull off this sort
of URL spoofing attack. Much work seems to have been done since the early 2000s
on the making homoglyph spoofing attacks readily apparent to the users. IE and
Chrome are a little better than Firefox from an anti-spoofing standpoint, while
perhaps not supporting IDNA as well. What we mean by this is that there are
times when the Unicode version should probably be shown instead of the Punycode
version for the sake of native language usability, but IE and chrome play it
safer from a spoofing standpoint. This was demonstrated by Firefox showing the
following as IDNs as Unicode, but IE and Chrome showing them as Punycode:
Íucu.org [xn--ucU+2ia.org] (Latin capital letter i with acute Í U+0456)
íucu.org [xn--ucU+qma.org] (Latin small letter i with acute í U+00ED)
iucu.org [xn--ucU+9ta.org] (Latin small letter i with ogonek i U+00ED)
Web apps also gave interesting results, showing odd parsing issues in how they
choose to anchor links. While it is not readily apparent how an attacker could
use this yet, it bares looking into.
For future work we plan to look more into other attack vectors using homoglyphs
such as further tests of username spoofing, filter evasion, canonicalization
errors and steganography.
References:
[1] A. Costello, March 2003. [Online]. Available:
http://www.ietf.org/rfc/rfc3492.txt .
[2] J. Abolins, December 2010. [Online]. Available:
http://www.irongeek.com/i.php?page=videos/dojocon-2010-videos#Internationalized%20Domain%20Names%20&%20Investigations%20in%20the%20Networked%20World
.
[3] M. Zalewski, The Tangled Web: A Guide to Securing Modern Web Applications,
1st ed., No Starch Press, 2011.
[4] E. &. G. A. Gabrilovich, "The Homograph Attack," Communications of the ACM ,
vol. 45, no. 2, 2002.
[5] V. Krammer, "Phishing defense against IDN address spoofing attacks," in
Proceedings of the 2006 International Conference on Privacy, Security and Trust:
Bridge the Gap Between PST Technologies and Business Services , New York, NY,
USA, 2006.
[6] E. Johanson, "The state of homograph attacks," 2005. [Online]. Available:
http://www.shmoo.com/idn/ . [Accessed 24
4 2012].
[7] D. Kennedy. [Online]. Available:
http://www.secmaniac.com/download/
.
[8] A. Crenshaw, 2012. [Online]. Available:
http://www.irongeek.com/homoglyph-attack-generator.php .
[9] phlyLabs, 2012. [Online]. Available:
http://phlymail.com .
[10] Microsoft, September 2006. [Online]. Available:
http://msdn.microsoft.com/en-us/library/bb250505%28VS.85%29.aspx .
[11] Chromium Project, [Online]. Available:
http://www.chromium.org/developers/design-documents/idn-in-google-chrome .
[12] C. Weber, July 2009. [Online]. Available:
http://www.blackhat.com/presentations/bh-usa-09/WEBER/BHUSA09-Weber-UnicodeSecurityPreview-SLIDES.pdf
.
[13] C. Weber, July 2009. [Online]. Available:
http://www.blackhat.com/presentations/bh-usa-09/WEBER/BHUSA09-Weber-UnicodeSecurityPreview-PAPER.pdf
.
[14] A. Crenshaw, "Steganographic Command and Control: Building a communication
channel that withstands hostile scrutiny," 2010. [Online]. Available:
http://www.irongeek.com/i.php?page=security/steganographic-command-and-control
. [Accessed 23rd April 2012].

 Printable version of this article
Printable version of this article